
In the ever-evolving realm of data analysis, the ability to extract meaningful insights from vast oceans of data is paramount. Enter K-Means Clustering—an algorithmic powerhouse that’s transforming the landscape of data analytics. As organizations strive to make sense of complex datasets, K-Means stands out as a tool that not only simplifies but also enhances understanding. Let’s delve into the mechanics of this algorithm and explore how it’s revolutionizing data analysis.
What is K-Means Clustering?
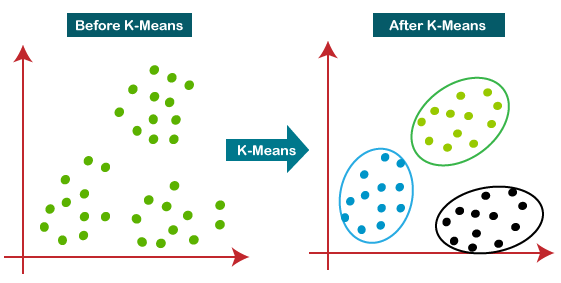
K-Means Clustering is a type of unsupervised machine learning algorithm used to categorize data into distinct groups or clusters. The fundamental idea is to partition a dataset into K different clusters, where each data point belongs to the cluster with the nearest mean. It’s a straightforward yet powerful method for uncovering natural groupings within a dataset.
The Mechanics of K-Means
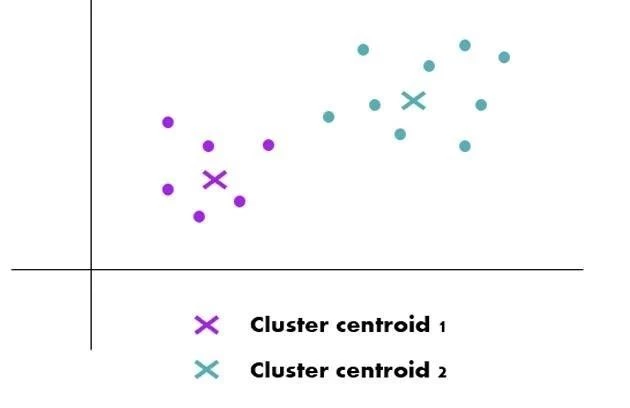
- Initialization: The algorithm begins by selecting K initial centroids randomly. These centroids are essentially hypothetical points in the data space.
- Assignment: Each data point is then assigned to the nearest centroid, forming K clusters.
- Update: The centroids are recalculated as the mean of all data points in each cluster.
- Iteration: The assignment and update steps repeat until the centroids stabilize, meaning they no longer shift significantly between iterations.
This iterative process ensures that the clusters are as compact and distinct as possible.
Applications Across Industries
The versatility of K-Means Clustering makes it applicable across various industries. Here are a few examples:
- Marketing: By segmenting customers into clusters based on purchasing behavior, companies can tailor marketing strategies to different audience segments, enhancing engagement and conversion rates.
- Finance: K-Means is employed to detect fraudulent activity by identifying unusual patterns in transaction data.
- Healthcare: In medical research, it aids in grouping patients with similar symptoms or genetic markers, leading to more personalized treatment approaches.
- Retail: Retailers use it to optimize inventory by clustering products based on sales data and customer preferences.
The Advantages of K-Means
One of the key strengths of K-Means Clustering is its simplicity and speed. As a computationally efficient algorithm, it can handle large datasets quickly, making it ideal for real-time data analysis. Additionally, its scalability allows it to grow with the increasing volume of data that modern businesses generate.
Challenges to Consider
Despite its advantages, K-Means Clustering does have some limitations. The need to predefine the number of clusters (K) can be tricky, as choosing the wrong number can lead to suboptimal clustering. Moreover, K-Means is sensitive to outliers, which can skew the results. To mitigate these challenges, it’s essential to preprocess data effectively and consider using techniques such as the Elbow Method to determine the optimal number of clusters.
The Future of Data Analysis with K-Means
As data continues to grow in complexity and volume, the role of K-Means Clustering in data analysis is poised to expand. With advancements in computational power and techniques to enhance its robustness, K-Means will remain a critical tool for businesses seeking to unlock actionable insights from their data.
In conclusion, K-Means Clustering is more than just a data analysis technique; it’s a catalyst for innovation and strategic decision-making. By transforming raw data into understandable patterns, it empowers organizations to make informed decisions, driving success in an increasingly data-driven world.
Great explanation of K-Means Clustering! The step-by-step breakdown helps demystify how the algorithm works, which is perfect for beginners looking to understand machine learning techniques.
I appreciate how the article highlights the practical applications of K-Means Clustering across different industries. It really shows the versatility and importance of this algorithm in real-world scenarios.
The article provides an excellent overview of K-Means Clustering and its significance in data analysis. It breaks down the algorithm into easy-to-understand steps, making it accessible even to those new to the field.
This is a well-written piece that succinctly captures both the theoretical and practical aspects of K-Means Clustering. It’s a must-read for anyone interested in data analytics.
I found the section on the mechanics of K-Means particularly insightful. It’s a concise yet thorough explanation that captures the essence of iterative clustering processes effectively.
The article does a fantastic job at illustrating how K-Means Clustering can enhance data understanding. The examples provided make it clear how businesses can leverage this tool for better decision-making.